With baseball and data on the brain, I decided to jump into a data engineering project that uses machine learning to create a prediction pipeline for MLB player performance.
Let's dive in.
🔧 Tools and concept
Major League Baseball maintains a public-facing API that provides player stats on a game-by-game basis. This data isn't as rich as the stuff you have to pay for, but it's still detailed enough to extrapolate the major advanced metrics used for player evaluation.
Starting with the raw MLB data, I wanted to set up an end-to-end data engineering pipeline that ingests game data, cleans it, calculates advanced metrics, then uses machine learning to predict player performance over time.
The stack
I chose the following tools to create my application
-
Apache Airflow (ETL and orchestration)
An industry standard for ETL and ELT flows, I chose Airflow because it provides a clean "Pythonic" API for orchestrating data. -
PostgreSQL (Database)
This one was a no-brainer. For a read-heavy system built for data analysis, PostgreSQL is the relational DB of choice. -
Scikit-Learn (Python machine learning library)
I wanted a Python ML library that was (relatively) lightweight and ergonomic; Scikit-Learn checks both boxes. -
Docker Compose (Containerization and dev env)
Docker Compose provides a containerization engine for local dev, even as the Airflow Docker distribution threatens to melt my CPU.
📁 Project structure
Database schema
Since this project is built for data analysis, and depends heavily on a core group of metrics, I decided to organize my database using a star schema.
A star schema organizes data into a central "fact" table, with foreign keys to various "dimension" tables, which contain metadata. This structure helps keep joins to a minimum when running queries.
Since my project dealt with player performance data on a game-by-game basis, I made player performance by game my central "fact", then created dimension tables for games, player metadata, teams, and dates.
ETL flow
My app contains two DAGs, one of which pulls, cleans, and loads data from the MLB API, the other of which references this data to make predictions about player performance.
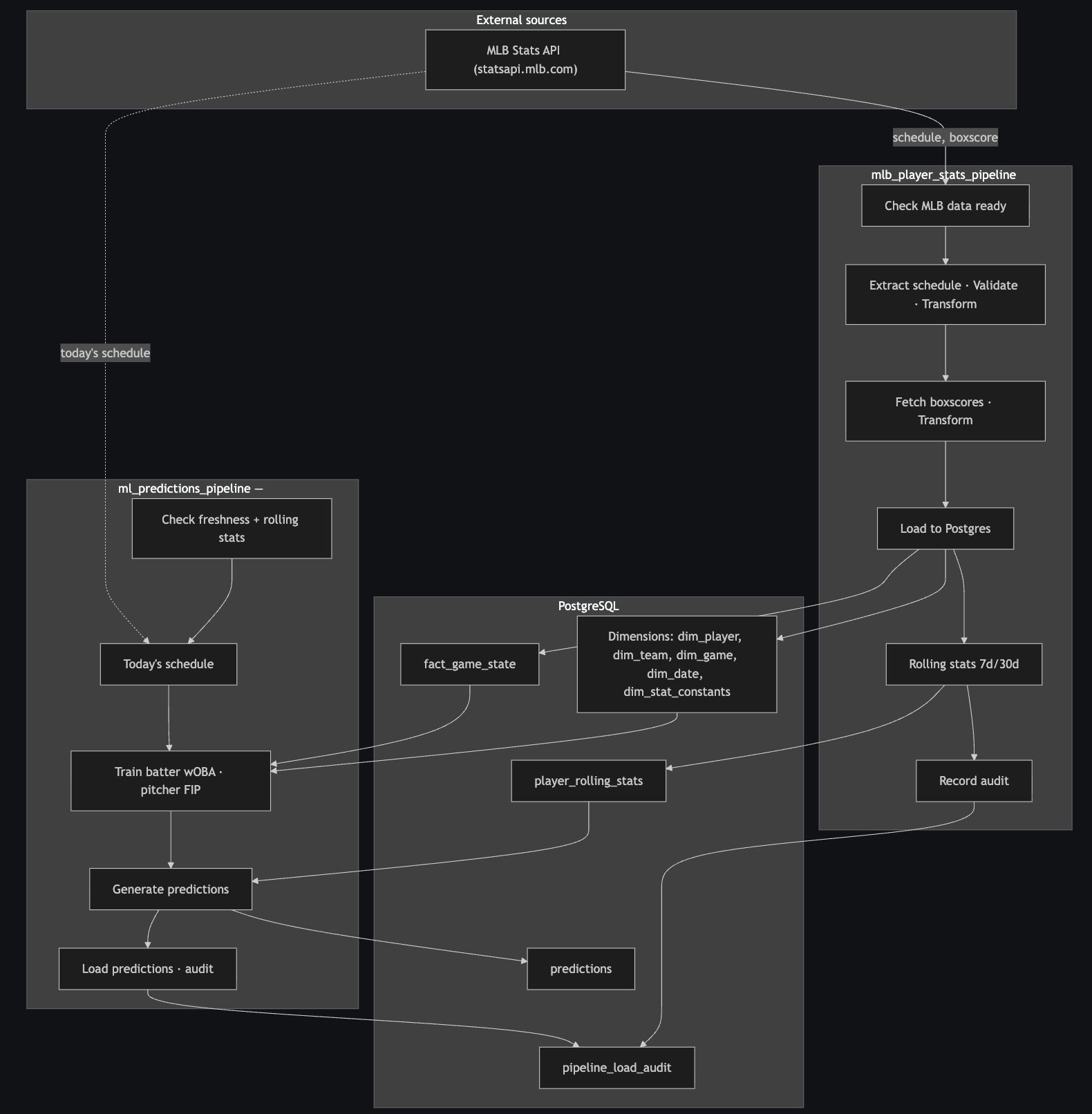
Player Stats Pipeline
Running at 2AM UTC each day, this pipeline polls the MLB API for fresh game data, extracts player performance, game, and team data from that payload, then loads the cleaned data into my database.
As mentioned above, my database for this project is organized via a star schema. This is obviously different than the format in which the MLB offers game data, so prior to loading it into my database, I have to organize player stats by game, calculate player advanced metrics, and extract my dimension data for insertion into its appropriate tables.
In order to ensure my data integrity, I validate my payload after calling the API, and after each transform. This also helps guarantee that my DAG remains idemponent — returning the same results for each date range, each time the process is called.
Prediction Pipeline
After I've loaded player performance data for the day, my prediction pipeline will look at that data and use it to make a prediction about each player's performance in the upcoming day's games.
Like my Player Stats pipeline, my prediction pipeline first checks for data freshness before going about its work. In the case that my database contains no data for the previous day, the pipeline aborts.
To start out with, I set my pipeline up to train toward a pair of key metrics: Weighted On-Base Average (wOBA) for batters and Fielding Independent Pitching (FIP) for pitchers.
A full explanation of why these metrics are predictive for player performance is outside the scope of this post, but it's fascinating stuff and I recommend you check it out; for the moment, just know that wOBA measures a player's omnibus offensive effectiveness and FIP measures a pitcher's effectiveness in a vacuuum, minus the contributions or faults of the remainder of his team.
Once the Prediction Pipeline has formulated its prediction, this prediction is uploaded to the database and the pipeline run is complete.
⚙️ Fine-tuning and refactors
Having laid out the basis of my pipelines, I went back and made a few changes to make the pipelines more robust and performant.
-
Error handling
I use Airflow's
on_failure_callbackhook to send email notifications that inform me whenever a pipeline run fails. -
Move advanced metric calculations to server
In an effort to reduce my pipelines' compute overhead, I moved the calculation of my advanced metrics out of Python and into a server-side process that runs using SQL. This will help offload expensive computations to cloud servers once in production.
-
Account for empty payloads
One problem I encountered immediately when backfilling my data was what to do with days on which there were no games played, for which the MLB's API returns an empty array with a 200 response code. I wrote fail-safes into both my pipelines to abort in the case of a day on which there are no games.
-
Create pipeline audit table
I added a table to record metadata about each of my pipeline runs (date, pipeline ID, success v. failure, etc.) in case I need to go back and audit later for failure points.
🔮 Future state
With the basics of my application in place, it's time to think about where the project can go from here.
-
Host and start recording data
This is the obvious one. I haven't uploaded this project to cloud hosting yet because of the costs, but I'd like to set it up on Digital Ocean App Platform, with a connection to Snowflake to hold the project's data.
-
Tune ML implementation
In the initial phase of this project, I focused primarily on ETL. I'd like to go back and fine-tune the predictive modeling by experimenting with different weights, traning towards different metrics, and setting multiple ML algorithms to work on the same project.
-
Set up "self-healing" pipelines
Implement generative AI tools to proactively fix pipelines in the event of a failure.
👋 Thanks for checking it out
It was exciting building Baseball Eval 1.0, but the real test will come once the MLB season begins. Once that happens, I'll be looking to make sure my pipelines can survive anamolies and data failures, and that my predictions are actually, you know, predictive.
I'll write a new post once we're a ways into the season, outlining how the app performed, and detailing any adjustments I made as a result.
In the meantime, thanks for checking it out and hit me up if there's anything about which you're curious.